Ja-ti: know who arrives, know who leaves
I’ve been shipping Ja-ti, a small product that tracks follower changes on X: who followed, who left, and the messy middle (suspended accounts, “gone” profiles, that sort of thing). The pitch fits on a line — know who arrives, know who leaves — but the implementation is where it gets interesting, because “compare two follower lists” sounds trivial until you’re doing it repeatedly, fairly across subscribers, within API and platform limits, and with billing that matches how expensive an account actually is to track.
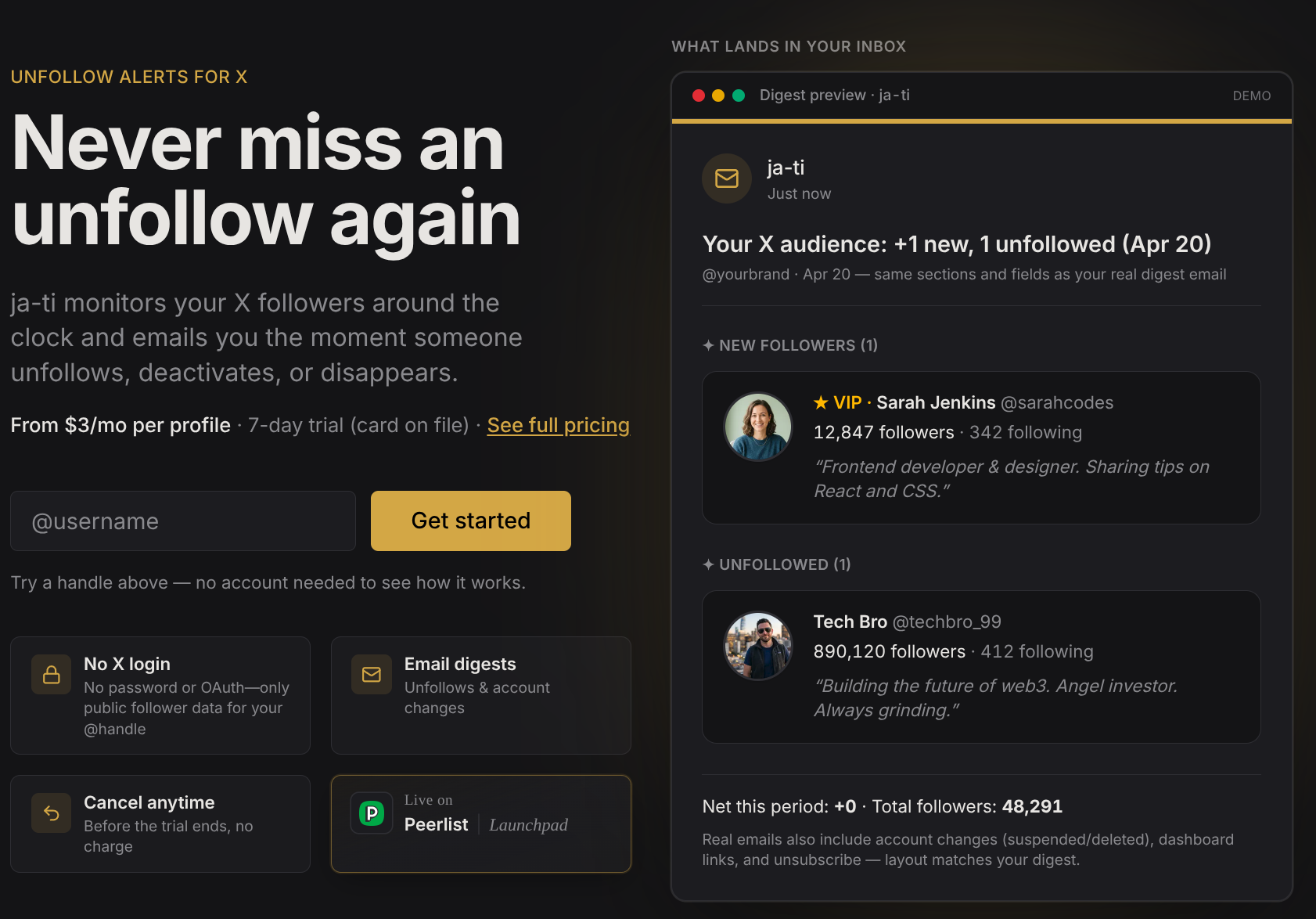
At a high level, Ja-ti takes the accounts you care about and checks them on a cadence you choose (within feasibility rules driven by audience size — you can’t promise a 15-minute sweep on a seven-figure follower count and mean it). It stores snapshots and diffs so you see history, not just a one-off delta. It sends digest email when something changed: new follows, unfollows, VIP-tier movements, account-status shifts — with tier-aware truncation so the entry experience doesn’t pretend every account gets a novel.
Billing is usage-shaped: list price scales with follower-count bands, there’s a card-required trial, and manual checks are gated differently from automatic runs so power users don’t accidentally erode margin. None of that needs a manifesto; it’s the boring truth of consumer infra products — the price has to track the cost, and the UX has to fail loudly when someone asks for the impossible.
Why the architecture isn’t “one big Worker”
The tempting v0 is: cron job, fetch followers, diff in memory, send email. That works until:
Multiple people track the same large account (you don’t want N redundant crawls).
Alarms and scheduling need per-canonical-user state, not a global queue that forgets whose interval is whose.
Follower enumeration is paginated and long — too long for a single request handler to own naïvely.
So Ja-ti splits responsibilities:
Postgres (via Cloudflare Hyperdrive) holds the durable truth: tracked accounts, snapshots, staging for big crawls, profile versions, billing-adjacent fields, webhook idempotency — the usual “this must survive a deploy” stuff.
A Durable Object per tracked X identity owns scheduling and subscriber-facing coordination — shared alarms, plan sync, the kind of state that’s painful to get right if you smear it across KV and hope.
Cloudflare Workflows run the follower-check pipeline: paginated fetch + persist, then finalize into a consistent snapshot, then diff / notify — with step budgets and safety caps so a pathological account becomes an ops problem, not a silent wrong answer.
The split matches how the platform wants you to think: Workflows for orchestration, DOs for strongly-owned singleton state, Postgres for queryable history.
The part that’s easy to underestimate: finalize
The crawl is only half the story. The other half is making partial progress invisible to readers: snapshots that aren’t complete shouldn’t look like the latest truth. Ja-ti leans on explicit complete flags, staging reads, and batched writes so finalize doesn’t devolve into thousands of round-trips or a single step that blows the Worker limit.
If you’ve ever watched a “simple” ETL catch fire on cardinality, this is the same genre — correctness and throughput are the same feature.
Typed boundaries (and why I care)
One meta-choice worth naming: the repo is intentionally strict at the edges. Typed contracts between the web app and the DO HTTP surface (via @firtoz/hono-fetcher — same idea as the Tab Canopy work: one clear contract) mean await res.json() carries the server’s Hono app types — no as as a coping strategy. That sounds precious until you’re iterating with agents and humans in the same codebase: the compiler becomes the checklist.
In-app billing uses Autumn; email goes out through Resend; X data through a provider API. The interesting glue is all in when you check, who pays for which cadence, and how you keep multi-subscriber accounts from fighting.
Where things stand
v1-shaped work is largely in place — band pricing, trials, VIP thresholds, crossover handling when someone’s audience moves bands, dashboard and history UX, optional PostHog, the whole “ship a real SaaS” package. The open threads are the usual second-order product work: finer pricing above large bands, optional email-density add-ons, and the long tail of mega-account honesty (disclosed caps, incremental strategies, or polite “out of scope” copy).
Ja-ti started as a straightforward idea and grew into a systems problem: fairness across subscribers, correctness under pagination, and pricing that tracks reality. That’s a good sign. The boring products are often the ones that teach you the most about platforms.
If you’re building something in this space — diffing social graphs under constraints — this is where I’ve been spending that energy lately.